AI Safety: The Final Frontier

Captain’s Log, Stardate 2023
In anticipation of the AI Safety Summit, set to be held this November, the international artificial intelligence (AI) landscape has ramped up the intensity of its discussion and research on developing protocols for the safe implementation of AI. The Summit aims to bring academics, governments, and industry experts from across the globe together to ‘grapple the challenges and opportunities presented through the rapid advancement of AI’.
In following this latest trend, the Department for Science, Innovation, and Technology (DSIT) this week published a discussion paper on Frontier AI (Discussion Paper), which goes on to highlight many of the capabilities (and subsequent risks and opportunities it poses) that will form the basis of many discussions over the course of the Summit.
Defining technology: A voyage into uncharted space…
The Discussion Paper targets several matters that are likely to form the subject of several heated discussions. Most obvious, and one subject to debate across the international community in the creation of new regulations, is pinning down what exactly do we mean when we talk about AI or Frontier AI.
The Discussion Paper acknowledges that this will continue to be a hotly debated issue in the development of international cooperation. For the purposes of the findings in Discussion Paper, the DSIT have settled on frontier AI being defined as:
“highly capable general-purpose AI models that can perform a wide variety of tasks and match or exceed the capabilities present in today’s most advanced models”.
This definition typically includes several of the large language models (LLMs) we see on the market today. The Discussion Paper does however note that while LLMs form the primary example at present, multi-modal models (such as those for generation of images, sound, and video) are also increasingly common, and this space is likely to develop as more advanced AI models emerge.
These technologies function through development in two main stages: i) pre-training prior to deployment and ii) fine-tuning once up and running.
In the pre-training phase, LLMs devour substantial quantities of text, documents, and other media. It begins to learn by predicting the subsequent word in a text, one word at a time. Initially, its predictions are quite random, but as it goes through more data, it learns from its errors and enhances its predictive accuracy. After the pre-training phase, the model becomes exceptionally good, even surpassing human abilities on occasion, in predicting the next word in a randomly selected document. It should be noted that these predictions do not always go to plan, as is detailed further below.
Once at the fine-tuning stage, the LLM continues training using carefully curated datasets. These datasets are designed for more specific tasks or are used to guide the model’s behaviour in line with the expected values and abilities assigned to the model.
Below is a diagram outlining this process and how the technology moves from development to deployment in practice.
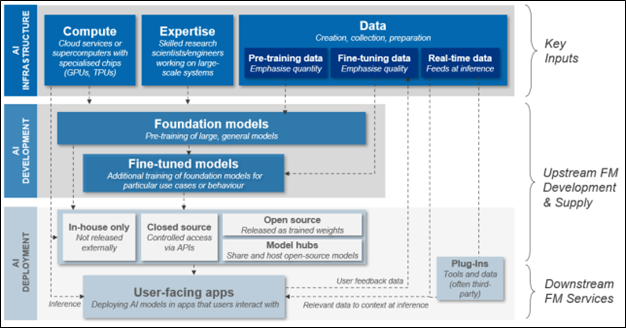
Image: Overview of foundation model development, training, and deployment. AI Foundation Models: Initial Review.
Things are only impossible until they’re not: Capabilities of Frontier AI
Frontier AI has been designed to perform a wide variety of tasks, whether this be to augment capabilities of those seeking to use the technology or to completely replace them in certain aspects of work (thereby allowing the user to focus on tasks that require a more ‘human’ touch. The following examples are highlighted in the Discussion Paper.
Economically Useful Tasks, which may include:
- Conversing fluently and at length, drawing on extensive information contained in training data, which may be used for cases such as chatbots.
- Writing long sequences of well-functioning code from natural language instructions, including making new apps, thereby speeding up development processes and lowering costs.
- Generating new content and assisting in the dissemination of information by news outlets.
- Translating between languages opening new opportunities for international business.
- Accelerating academic research, leading to new innovations and developments for the good of society.
As noted above, frontier AI performs best when augmented to existing team members and tools. The Discussion Paper highlights this with an example of augmenting an LLM to existing search repositories, such as a web browsers, which then excels in assisting in the development of strategies that an employee or researcher could take in their pursuit of a defined goal.
What remains apparent amidst all these exceptional discoveries and possibilities, is that frontier AI may be much more capable than we have been able to determine, and the industry continues to learn together as we push the limits of the technology.
It is expected that with enhancements such as: better prompts, better tools that can be augmented, better structures of information flow, more appropriate fine-tuning of data, and the cooperation of multiple AI systems, that brand new capabilities will begin to emerge, thereby revolutionizing further aspects of all the work we do.
I’m giving her all she’s got: Technical limitations of Frontier AI
As with all technologies, frontier AI is not without its limitations. Much of the performance relies heavily on the foundation on which it sits. If the model created does not meet the needs of the proposed task, or the data used is not representative, accurate, or adequately curated, then the AI will not perform as intended, regardless of how much information it is fed or how many times you seek to correct its behaviour.
The result of these limitations, as the Discussion Paper highlights may lead to:
- Hallucinations – AI systems may often provide plausible but incorrect answers with high confidence which, if not appropriately monitored, may cause issues for those seeking to rely on the output.
- Coherence over extended durations – AI can often struggle with tasks requiring extended planning or a large number of sequential steps, such as writing extended pieces (largely due to their limited ability to retain context over longer tasks).
- Lack of detailed context – Many of the tasks faced in the real-world require an understanding of specific context (often learned through experience). While AI systems are generally competent, as noted above, they do not understand the reasoning behind why certain predictions or outputs are intended or make sense. This can lead them to producing inaccurate outputs through use, as they are not yet unable to fully understand why certain outputs are sought or the reasoning behind a user’s request.
The Next Generation: How might Frontier AI Improve in Future?
The positive (or negative depending on stance on AI) within these limitations is that they have been documented and identified. Many are therefore working on improving system capabilities – a process which is developing at rapid speed.
The Discussion Paper considers three primary causes for development at such speed:
- Computing Power – This refers to the number of operations that an AI system can perform (which is typically determined at the point of training). Compute power over the past 10 years has grown drastically with no immediate signs of slowing and is currently being fueled through technical improvements to hardware and investment in compute innovation.
- Data – Training has also rapidly improved over the last 10 years due to a substantial increase in availability of raw data and curated data sets. As with compute power, it is expected that this is to continue to grow, with the Discussion Paper indicating this has continued at a rate of 50% every year.
- Improvements in underlying infrastructure – In addition to compute and data, we are also seeing a drastic improvement in the development of models and tools. Enhancements at the post-training stage continue to allow developers to push the boundaries of their models and create more effective systems for individual use or as augmentations to existing tools.
The developments, often the subject of international media reports, are not the result of single breakthroughs, but rather a collective effort by researchers, industry, and experts in their respective fields (including algorithms, investment in compute power, and post-training developments). The Discussion Paper notes that while this speed is expected to continue for the next few years, it will become much more difficult to maintain this pace after 2030 and new approaches will therefore require development. Such additional measures could take the form of greater enriched data (such as through synthetic data), multi-modal training in order to increase synergies between existing tools, and access to larger training resources, such as autonomous scraping of internet resources.
Shields up: Risks and challenges of Frontier AI
Working at the bleeding edge of technology is not without its risks – a fact which is exacerbated by the inability of regulators to keep pace with such rapid advances. Organisations must therefore be cognizant of the various risk vectors that the use of such innovative technologies brings.
These include:
- Difficulty in designing frontier AI in a safe manner if open-ended domains are used. Use of open-ended domains (resources available to developers from the public such as open-source models and code) often makes a model much more susceptible to security risks, therefore reducing the technical robustness of a tool developed on that basis.
- Safety testing of frontier models is an open challenge on a moving target. With no defined safety standards or best practices, the target is always moving on how to test the overall safety of frontier AI. Organizations across the world, including DLA Piper, have therefore developed their own methods of evaluating the trust and safety of these models.
- There is no clear method of easily monitoring deployment and use of frontier models. Unless specific measures have been baked into a frontier AI model, it is difficult for developers to maintain oversight of how their tools are being used, which may lead to liability issues in future where appropriate care on limiting use cases has not been factored.
- The industry is working in a vacuum of safety standards and regulatory guidelines. This means that the technical robustness or overall safety of frontier models varies across the industry and users may find difficulty in determining which risk profile is most appropriate for them in their deployment of AI.
- Tools can be used for malevolent purposes. It is difficult to determine who may use a tool in a way that does not benefit society. We are already quickly seeing the potential for frontier models to produce inaccurate information, ‘fake news’ and false media, which may confuse the public and sway important democratic processes.
- AI has the future potential to limit how humans can monitor its behaviour. While this concern has not fully come to fruition, AI is rapidly developing means of acting outside of the oversight of humans, such as AI which develops its own language to communicate with other systems. If suitable care is not taken, we may quickly lose control of the tools we develop.
Such risks are by no means a reason for frontier AI to be restricted or prohibited from developing. Instead, organizations, researchers, and developers should take care in ensuring that the benefits of its use are carefully protected through comprehensive governance frameworks and internal safety mechanisms.
Find out more
For more information on AI and the emerging legal and regulatory standards, visit DLA Piper’s focus page on AI.
Gain insights and expert perspectives that will help shape your AI Strategy. Pre-register here.
DLA Piper continues to monitor updates and developments of AI and its impacts on industry across the world. For further information or if you have any questions, please contact Coran Darling, Mark O’Conor, Tim-Clement Jones, or your usual DLA Piper contact.